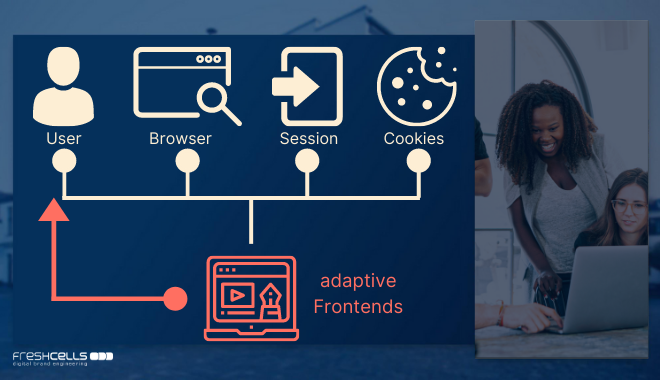
Die Liste an möglichen Daten und Datenquellen macht deutlich: nur die wenigsten Daten können direkt verwendet werden, um ein Frontend so zu adaptieren, dass die Nutzung für einzelne Nutzerinnen und Nutzern angenehmer und mehrwertiger wird. Die meisten Daten brauchen Interpretationen und liefern erst in der Kombination mit anderen wichtige Erkenntnisse. An dieser Stelle kommen Mechanismen und Methoden von Big Data ins Spiel.
Aber schauen wir noch einmal genauer auf die Daten und fangen mit den low hanging fruits an.
Die Abfrage von Präferenzen in den Profileinstellungen und die Abfrage von Unternehmenseigenschaften, Rolle und ähnliches mehr liefert einfache Indikatoren. Stellt eine Nutzerin bzw. ein Nutzer eine Währung als bevorzugte Währung ein, dann ist klar, wie sich das Frontend anpassen muss.
Auch die Angabe des Endgeräts kann einfach genutzt werden – und wird auch in fast allen Websites genutzt – durch ein responsives Design.
Was aber ist mit Verhaltensinformationen, mit Alter, Geschlecht und so weiter, wenn dem gegenüber keine 1:1-Beziehung zum Beispiel im Produktportfolio steht?
Aus der Kombination von Informationen ergeben sich prototypische Profile, die wahrscheinlich auch prototypische Bedürfnisse und Vorlieben haben. Darauf kann eine Applikation ebenfalls reagieren.
Allerdings funktioniert die Übersetzung anders. Bei der Betrachtung von Nutzungsprofilen gilt es, mehrere Informationen zusammenzufügen, diese zu interpretieren und mit Annahmen zu reagieren. Auch müssen die Annahmen validiert werden, um keinen Fehlinterpretationen aufzusitzen.
Ebenfalls stellt sich die konzeptionelle Frage, wie die Reaktionsgenauigkeit aussehen soll. Soll die Applikation verschiedene Frontend-Varianten bereithalten, die jeweils auf ein oder mehrere Prototypische Nutzungsprofile passen oder soll die Applikation pro Funktion die Profile interpretieren? Und wenn ja, sind die Profile immer dieselben oder werden diese immer wieder neu entwickelt?
Und letztendlich stellt sich die Frage, was der Anspruch an die Adaptionen ist. Zieht die 80:20-Regel oder soll jede einzelne Nutzerin und jeder einzelne Nutzer sich zu 100% wiederfinden? Wäre eine solche Flexibilität überhaupt noch steuerbar?
Wahrscheinlich nicht oder zumindest nicht wirtschaftlich. Bietet dass eine Prozent, das vielleicht einen ganz eigenen Ansatz bräuchte, um die Applikation zu 100% zu lieben und intensiv zu nutzen, soviel wirtschaftlichen Mehrwert, dass sich der Aufwand rechnet?
Die Frage nach dem richtigen Konzept und dem Grad der Flexibilität ist dann durch die wirtschaftliche Strategie des anbietenden Unternehmens bestimmt.
Technologie definiert die Möglichkeiten und den Aufwand. Mit der richtigen Architektur und den richtigen Algorithmen lassen sich viel mehr individuelle Präferenzen bedienen und eröffnen Optionen.